
Kürzlich war ich auf Jobsuche, habe dafür Google und Facebook genutzt – und wurde dabei sehr wahrscheinlich diskriminiert, weil ich eine Frau bin. Denn die Computer-Algorithmen der großen Tech-Firmen entscheiden nach ziemlich traditionellen Geschlechter-Stereotypen, welche Jobanzeigen Frauen und welche Männern angezeigt werden:
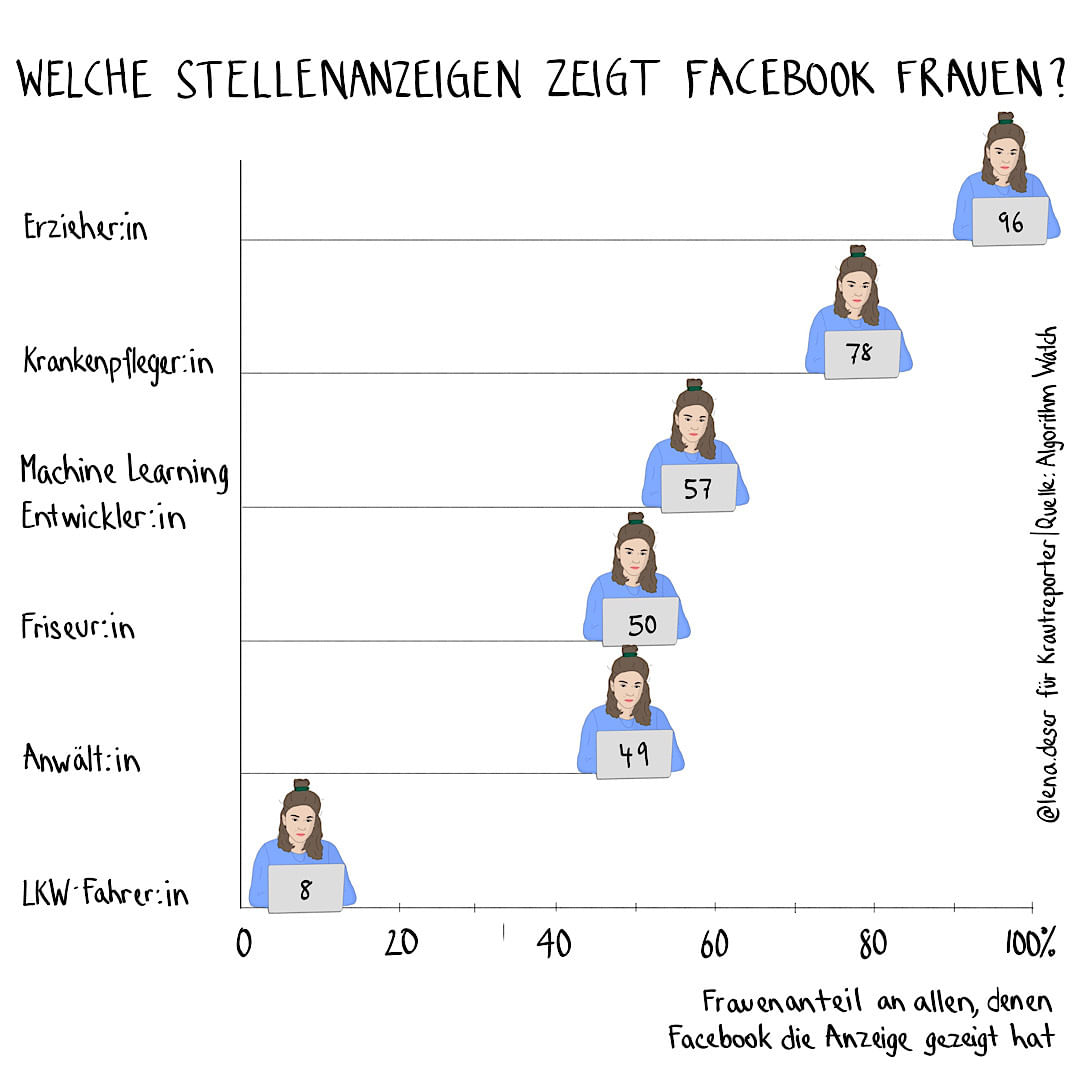
@lena.deser für Krautreporter / Quelle: Algorithm Watch
Für den Algorithmus ist entscheidend, welche Nutzer:innen in der Vergangenheit auf ähnliche Anzeigen geklickt haben. Gesellschaftlichen Kontext bezieht er dabei natürlich nicht mit ein.
Warum interessieren sich Frauen auch im Jahr 2020 häufiger für den Beruf der Friseurin als für den des Programmierers? Weil Frauen und Männer nun mal einfach so sind oder weil sexistische Strukturen Frauen und Männern bestimmte Eigenschaften zuschreiben und andere absprechen?
Noch ein Beispiel: Özlem Türeci und Uğur Şahin sind gerade in aller Munde, weil die beiden verheirateten Mediziner:innen gemeinsam einen Corona-Impfstoff in ihrem gemeinsamen Unternehmen Biontech entwickelt haben. Aber Google gab die Qualifikation der beiden so an:

@lena.deser für Krautreporter
Uğur Şahin war Vorstand und Özlem Türeci Ehefrau. Die Google-Informationsfelder werden anhand von Informationen aus dem Web automatisch generiert und halten uns damit einen Spiegel vor: Obwohl die Eheleute den Impfstoff gemeinsam entwickelt haben, stand in der medialen Berichterstattung vor allem Uğur Şahin im Vordergrund – in der Bild-Zeitung zum Beispiel als „Vater des deutschen Impfstoff-Wunders“. Google hat mittlerweile die sexistische Kurzbiografie von Özlem Türeci geändert. Ich fühle mich zurückversetzt in die 1950er Jahre, als Ehefrauen von Ärzten noch mit „Frau Doktor“ angesprochen wurden.
Wie kann das alles sein? War es nicht das hoffnungsvolle Versprechen von Algorithmen, dass sie Entscheidungen objektiv, neutral und effizient treffen würden – anders als subjektive, vorurteilsbelastete, langsame und fehleranfällige Menschen?
Algorithmen treffen Entscheidungen mit weitreichenden Folgen⬆ nach oben
Algorithmen sind nicht neu, kein Taschenrechner funktioniert ohne sie. Viele Algorithmen vereinfachen unser Leben. Ich freue mich jede Woche, über meine Spotify-Playlist neue Künstler:innen zu entdecken.
@lena.deser für Krautreporter
Algorithmen treffen aber auch Entscheidungen mit weitaus dramatischeren Auswirkungen: Das Bundesamt für Migration und Flüchtlinge vergleicht mit Hilfe einer Spracherkennungssoftware Handydaten mit dem Klang der angegebenen Erstsprache von Asylbewerber:innen, um deren Herkunftsland zu überprüfen. Die Polizei verwendet Computerprogramme, um mögliche Kriminalitätsbrennpunkte zu identifizieren. In manchen Frauenhäusern wird ein Tool eingesetzt, um das Gewaltrisiko männlicher (Ex-)Partner zu bestimmen. Der von Algorithmen berechnete Schufa-Score ermittelt die Kreditwürdigkeit von Menschen und beeinflusst damit, wer einen Kredit aufnehmen, einen Handyvertrag abschließen oder eine Wohnung mieten kann. Gesichtserkennungssoftware soll bei Massenveranstaltungen potentielle Gefährder:innen erkennen, indem die Software Emotionen in der Mimik von Menschen interpretiert.
Nicht alle, aber immer mehr Algorithmen arbeiten dabei auf Basis des sogenannten maschinellen Lernens. Dabei „lernt“ ein Algorithmus anhand von Daten bestimmte Muster, die er dann nutzt, um Entscheidungen und Vorhersagen zu treffen. Diese Muster ergeben sich daraus, dass bestimmte Dinge häufig zusammen auftreten. Im Fall der Gesichtserkennung etwa lernt ein Computer anhand einer riesigen Menge an Fotos menschlicher Gesichter, diese als solche zu erkennen.
Algorithmen tun das aber nicht komplett ohne Menschen. Menschen entscheiden zum Beispiel, mit welchen Daten ein Algorithmus was genau lernt – und plötzlich ist der Algorithmus eben doch nicht mehr objektiv und neutral.
Wenn rassistische Algorithmen dein Gesicht nicht erkennen⬆ nach oben
Joy Buolamwini, afroamerikanische Informatikerin und Aktivistin, bemerkte bei ihrer Arbeit mit einer Gesichtserkennungssoftware, dass diese ihr Gesicht nicht erkannte – bis sie eine weiße Maske aufsetzte.

@lena.deser für Krautreporter
Davon motiviert, untersuchte Joy Buolamwini gemeinsam mit ihrer Kollegin Timnit Gebru die Gesichtserkennungssoftwares von Microsoft, IBM und Face++. Diese Programme erkennen nicht nur Gesichter, sie kategorisieren diese auch – im binären Frau-Mann-Schema – nach Geschlecht. Was ist aber mit Menschen, die nicht in dieses binäre Frau-Mann-Schema passen (wollen)? Auch wenn die Unterscheidung in nur zwei Geschlechter in unserer Gesellschaft bis heute vorherrscht und ziemlich wirkmächtig ist – die Annahme, es gebe nur zwei Geschlechter, ist (auch naturwissenschaftlich) eigentlich längst überholt.
Außerdem fanden die beiden Forscherinnen Buolamwini und Gebru heraus, dass alle drei Programme das Geschlecht der Gesichter von Schwarzen Frauen in über einem Drittel der Fälle falsch einordneten. Weiße Männer hingegen erkannten die Programme beinahe perfekt.
Das ist nicht nur ärgerlich, wenn dein I-Phone deine Fotos nicht richtig sortiert. Es kann im schlimmsten Fall dazu führen, dass du fälschlicherweise im Gefängnis landest oder nicht durch die Passkontrolle im Flughafen kommst. Wenn du Schwarz bist.
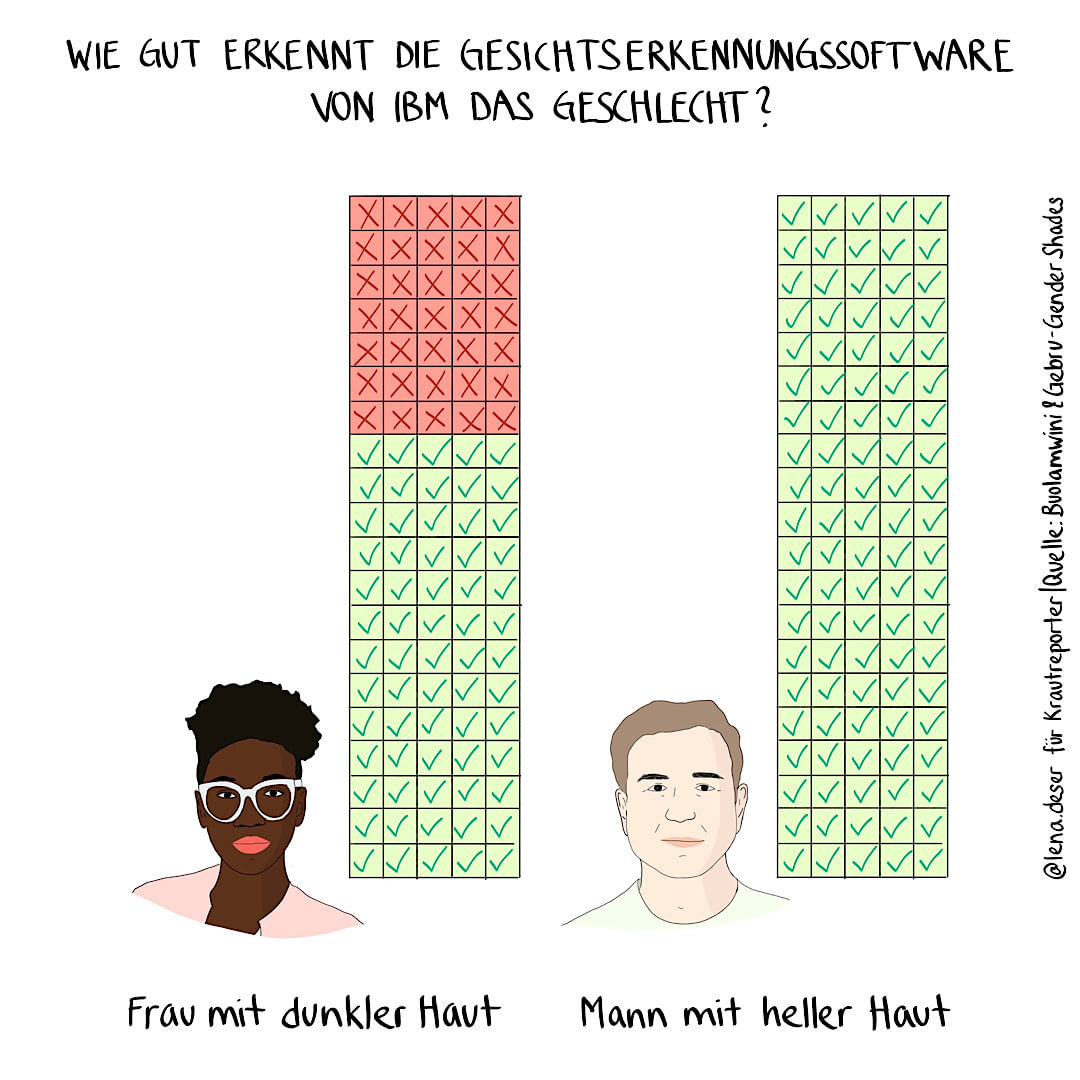
@lena.deser für Krautreporter / Quelle: Buolamwini & Gebru - Gender Shapes
Die US-amerikanische Forscherin Lauren Rhue fand auch in einer Software, die Gefühle interpretiert, eine rassistische Verzerrung: Die getesteten Gesichtserkennungssoftwares ordneten den Gesichtern Schwarzer Männer mehr negative Emotionen zu als den Gesichtern weißer Männer.
Das Problem: Die Datensätze, mit welchen die Algorithmen trainiert wurden, waren einseitig und nicht divers. Oder anders gesagt: Sie spiegelten die Wirklichkeit nicht wider.
Offenbar ist keinem der Software-Entwickler:innen aufgefallen, dass die Fotos, mit denen die lernenden Algorithmen programmiert wurden, überwiegend weiße Männer abgebildet haben. Da hilft es nicht, wenn diejenigen, die die Algorithmen programmieren, selbst überwiegend weiße Männer sind: Im Jahr 2020 sind weltweit weniger als ein Viertel der Mitarbeiter:innen in technischen Berufen bei Microsoft und Facebook Frauen. Für trans- und intergeschlechtliche sowie non-binäre Menschen gibt es keine offiziellen Zahlen. In den USA sind aktuell unter vier Prozent der Mitarbeiter:innen in technischen Berufen bei Microsoft Schwarz. Bei Facebook sind es sogar nur unter zwei Prozent.
Der Algorithmus setzt „lesbisch“ mit „Porno“ gleich⬆ nach oben
Ein anderer Weg, wie Vorurteile in die Algorithmen gelangen: Algorithmen lernen (oftmals selbstständig und damit unbemerkt und nur schwer durchschaubar) anhand von Daten, die unsere Realität sehr gut widerspiegeln – und damit eben auch gesellschaftliche Ungerechtigkeiten. Bestehende gesellschaftliche Ungleichheiten werden quasi in den Algorithmus hinein programmiert. Zum Beispiel, wenn LGBTQ+-Inhalte im Internet von Algorithmen automatisch zensiert werden.
Als ich kürzlich für eine Recherche das Buch „We Have Always Been Here“ von Samra Habib auf Amazon suchte, musste ich feststellen, dass das Buch, in dem eine queere Frau auf einfühlsame Weise über ihr Aufwachsen und ihre Erfahrungen als queere, muslimische und migrantische Frau of Color in Kanada schreibt, als „Erotik-Literatur“ klassifiziert ist. Ob auch dahinter ein Algorithmus steckt? Jedenfalls bin ich nicht die Erste, die darauf aufmerksam wurde, dass Amazon Bücher mit LGBTQ+-Inhalten automatisch als „nicht jugendfrei“ bezeichnet.
Auch Youtube-Algorithmen scheinen ein Problem mit LGBTQ+-Inhalten zu haben. Als ich beispielsweise das Video „We Might Be Dead By Tomorrow“ der bisexuellen Sängerin Soko auf Youtube suchte, wurde ich von Youtube nach meinem Alter gefragt – mit dem Hinweis, die Inhalte des Videos könnten für manche Nutzer:innen unangemessen sein. Ein Liebeslied („Gib mir all deine Liebe, denn nach allem, was wir wissen, könnten wir morgen schon tot sein“) mit einem Video, das die Liebe zweier Frauen zelebriert, ist nicht jugendfrei?
Für einen kleinen Vergleich: „WAP“ („Wet-Ass-Pussy“, auf Deutsch „arschnasse Mus**i“) von Cardi B und Megan Thee Stallion („Ich will nicht spucken, ich will schlucken, ich will würgen, ich will ersticken, ich will, dass du das kleine baumelnde Ding berührst, das hinten in meinem Hals schwingt“) ist auf Youtube jugendfrei und wird medial als weibliche Selbstermächtigung gefeiert. Mit diesem Vergleich will ich nicht über die Lust von zwei der erfolgreichsten Rapperinnen überhaupt urteilen, sondern auf die unterschiedlichen Maßstäbe aufmerksam machen.
Eine Untersuchung legt nahe, dass Youtube Bots (automatisierte Computerprogramme) verwendet, die selbstständig eigene Listen mit Schlüsselwörtern erstellen. Anhand dieser Listen entzieht Youtube bestimmten Videos die Werbeeinnahmen. Laut der Untersuchung wurden Videos, die mit „gay“ (schwul) oder „lesbian“ (lesbisch) getagged waren, als nicht werbetauglich eingestuft. Wurden die Begriffe „gay“ oder „lesbian“ durch „happy“ (glücklich) ersetzt, waren exakt die selben Videos wieder werbetauglich. Vergangenes Jahr reichten mehrere LGBTQ+-Youtuber eine Klage gegen den Mutterkonzern Google ein, in der sie behaupten, dass sie durch den Youtube-Algorithmus eingeschränkt, zensiert und finanziell geschädigt werden würden.

@lena.deser für Krautreporter
Doch die Gleichsetzung von LGBTQ+-Inhalten mit pornografischen, nicht-jugendfreien Inhalten betrifft nicht nur Youtube: Um sicherzustellen, dass Unternehmen mit ihrer Werbung nicht neben unpassenden oder unangemessenen Inhalten im Internet erscheinen, nutzen sie Sicherheitsprogramme, die Schlüsselwörter kennzeichnen. Eine Untersuchung der University of Baltimore und dem Sicherheitsunternehmen CHEQ kam zu dem Ergebnis, dass bis zu 73 Prozent der neutralen oder positiven LGBTQ-Online-Nachrichten von diesen Programmen fälschlicherweise als pornografisch gekennzeichnet wurden.
Wenn ein Algorithmus „lesbisch“ als Pornokategorie und „schwul“ als Schimpfwort kennzeichnet, ist das nicht nur verletzend, weil damit meine Liebe zu meiner Partnerin und meine Lebensweise sexualisiert, objektifiziert und degradiert werden. Es ist auch gefährlich, weil dadurch die Informationen, Geschichten und Stimmen, die wir LGBTQ+-Menschen so dringend brauchen, unsichtbar gemacht werden.
Kritiker:innen setzen ihren Job aus Spiel⬆ nach oben
Algorithmen gehören längst zu unserem Alltag, doch wer auf die ethischen Aspekte hinweist, setzt damit potenziell den eigenen Job aufs Spiel. Das zeigt der aktuelle Fall von Timnit Gebru. Die renommierte Wissenschaftlerin arbeitete bis Anfang Dezember 2020 als Co-Leiterin des Ethical AI Intelligence Teams bei Google. Gemeinsam mit anderen Forscher:innen hatte sie einen Bericht geschrieben, in dem sie auf unterschiedliche diskriminierende und klimaschädliche Implikationen von bei Google verwendeten Technologien hinweist. Doch Google wollte diese Forschungsergebnisse nicht veröffentlichen, stattdessen wurden die Forscher:innen aufgefordert, den Bericht zurückzuziehen. Nachdem Gebru in einer internen E-Mail an eine Gruppe von Frauen und Verbündeten über diesen Streit berichtete und ihrem Arbeitgeber vorwarf, kritische Stimmen zum Schweigen bringen zu wollen, wurde ihr fristlos gekündigt.
Dabei brauchen wir diese Debatten so dringend: Im Ende Oktober erschienenen Bericht „Automating Society“ der gemeinnützigen Organisation Algorithmwatch in Zusammenarbeit mit der Bertelsmann Stiftung warnen die Autor:innen, dass immer mehr algorithmische Entscheidungssysteme zum Einsatz kommen, ohne dass es eine breite gesellschaftliche Debatte gibt. Viele Menschen glauben vielleicht, dass sie zu so einem „technischen“ Thema nichts zu sagen haben. Doch für die Beschäftigung mit Algorithmen – und vor allem mit den gesellschaftlichen Folgen von Algorithmen – brauchen wir kein Informatikstudium.
Algorithmen sind weder neutral noch objektiv. Sie sind von Menschen gemacht und spiegeln deshalb die Ungleichheitsverhältnisse unserer Gesellschaft wider. Im schlimmsten Fall diskriminieren sie unbemerkt Millionen von Menschen.
Deswegen müssen wir diskutieren, welche Algorithmen Entscheidungen und Vorhersagen über Menschen treffen, welche Algorithmen überhaupt sinnvoll sind (zum Beispiel weil sie tatsächlich bessere Entscheidungen treffen als Menschen) und welche Algorithmen wir aus ethischen Gesichtspunkten heraus (nicht) wollen.
Redaktion: Rico Grimm, Schlussredaktion: Theresa Bäuerlein, Fotoredaktion: Till Rimmele